 SundayHK
SundayHK
AMQP
AMQP,即Advanced Message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。 那么再来介绍下RabbitMQ本身。RabbitMQ是一个上面说的AMQP协议的开源实现,其服务器端用Erlang语言写的,支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX。该消息队列主要用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
为何要选型RabbitMQ
- (1)RabbitMQ本身安装部署(单实例/集群)均较为简单,上手门槛低,功能丰富,符合AMQP标准;
- (2)RabbitMQ的集群易于扩缩,可以根据实际的业务访问量,通过增减集群中节点实例的方式,达到弹性扩容、缩小的效果;
- (3)企业级消息队列中间件,经过业界各个公司生产环境大量实践案例的验证,具有较高的可靠性;
- (4)提供各种插件,比如RabbitMQ Management插件提供友好的Web页面管理;
- (5)除了Web页面可以对RabbitMQ的单实例和集群的各种参数(Exchanges/Queues/Connections等)进行监控以外,其还提供Http的Api接口/JMX接口可以方便用户根据业务需求进行各种自定义的MQ级监控;
- (6)支持消息持久化、支持消息确认机制、灵活的任务分发机制等,支持功能非常丰富;
- (7)实现高可用性,可以在RabbitMQ集群中的机器上创建队列的镜像,使得在部分节点出问题的情况下队列仍然可用;此外,其warren和Shovel模式,可以实现故障转移能力和跨数据中心的异地复制;
RabbitMQ消息队列基本概念

(1)Broker Server:维护一条从Producer到Consumer的路线(Connection),保证数据能够按照指定的方式进行传输。
(2)Virtual Host,表示一批交换器、消息队列和相关对象的容器。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。默认的 vhost 是 “/”;
(3)Connection: 连接,Producer和Consumer都是通过TCP连接到RabbitMQ Server的。一般我们会看到,在我们业务代码的起始为止就是建立这个TCP连接。
(4)Channels: 信道,它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,代码开始处第一步是先建立TCP连接(上面(2)步骤),第二步就是建立这个Channel。
(5)Exchange:消息的生产者将消息发送到Exchange(交换器),由Exchange将消息路由到一个或多个Queue中(或者丢弃)。Exchange并不存储消息。RabbitMQ中的Exchange有fanout、direct、topic、headers四种类型,每种类型对应不同的路由规则。其中,headers 匹配 AMQP 消息的 header 而不是路由键,此外 headers 交换器和 direct 交换器完全一致,但性能差很多,目前几乎用不到了,所以一般在业务应用中只需要关注其他三种类型即可:
direct:消息中的路由键(routing key)如果和 Binding 中的 binding key 一致, 交换器就将消息发到对应的队列中。路由键与队列名完全匹配,如果一个队列绑定到交换机要求路由键为“dog”,则只转发 routing key 标记为“dog”的消息,不会转发“dog.puppy”,也不会转发“dog.guard”等等。它是完全匹配、单播的模式;fanout:每个发到 fanout 类型交换器的消息都会分到所有绑定的队列上去。fanout 交换器不处理路由键,只是简单的将队列绑定到交换器上,每个发送到交换器的消息都会被转发到与该交换器绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。fanout 类型转发消息是最快的;topic:交换器通过模式匹配分配消息的路由键属性,将路由键和某个模式进行匹配,此时队列需要绑定到一个模式上。它将路由键和绑定键的字符串切分成单词,这些单词之间用点隔开。它同样也会识别两个通配符:符号“#”和符号“”。#匹配0个或多个单词,匹配不多不少一个单词;
(6)Queue:队列,其为RabbitMQ的内部对象,用于存储消息。消息消费者就是通过订阅队列来获取消息的,RabbitMQ中的消息都只能存储在Queue中,生产者生产消息并最终投递到Queue中,消费者可以从Queue中获取消息并消费。多个消费者可以订阅同一个Queue,这时Queue中的消息会被平均分摊给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理。
(7)RoutingKey:生产者在将消息发送给Exchange的时候,一般会指定一个routing key,用于指定这个消息的路由规则。而这个routing key需要与Exchange Type及binding key联合使用才能最终生效。在Exchange Type与binding key固定的情况下(在正常使用时一般这些内容都是固定配置好的),我们的生产者就可以在发送消息给Exchange时,通过指定routing key来决定消息流向哪里。RabbitMQ为routing key设定的长度限制为255 bytes。
RabbitMQ这款消息队列中间件产品本身是基于Erlang编写,Erlang语言天生具备分布式特性(通过同步Erlang集群各节点的magic cookie来实现)。因此,RabbitMQ天然支持Clustering。这使得RabbitMQ本身不需要像ActiveMQ、Kafka那样通过ZooKeeper分别来实现HA方案和保存集群的元数据。集群是保证可靠性的一种方式,同时可以通过水平扩展以达到增加消息吞吐量能力的目的。
配置host解析(所有节点)
cat << EOF >> /etc/hosts
192.168.10.101 node1
192.168.10.102 node2
192.168.10.103 node3
...
192.168.10.100 haproxyRabbitMQ安装
配置erlang https://www.erlang-solutions.com/downloads/
wget https://packages.erlang-solutions.com/erlang-solutions-2.0-1.noarch.rpm
rpm -Uvh erlang-solutions-2.0-1.noarch.rpm配置rabbitmq https://www.rabbitmq.com/install-rpm.html
curl -s https://packagecloud.io/install/repositories/rabbitmq/rabbitmq-server/script.rpm.sh | sudo bash
## primary RabbitMQ signing key
rpm --import https://github.com/rabbitmq/signing-keys/releases/download/2.0/rabbitmq-release-signing-key.asc
## modern Erlang repository
rpm --import https://packagecloud.io/rabbitmq/erlang/gpgkey
## RabbitMQ server repository
rpm --import https://packagecloud.io/rabbitmq/rabbitmq-server/gpgkey安装erlang rabbitmq
sudo yum install erlang rabbitmq-server修改data log路径
mkdir -p /data/rabbitmq/mnesia
mkdir -p /data/logs/rabbitmq
chown -R rabbitmq.rabbitmq /data/rabbitmq/mnesia /data/logs/rabbitmq
cat << EOF >> /etc/rabbitmq/rabbitmq-env.conf
RABBITMQ_MNESIA_BASE=/data/rabbitmq/mnesia
RABBITMQ_LOG_BASE=/data/logs/rabbitmq
EOF启动rabbitmq
systemctl enable rabbitmq-server
systemctl start rabbitmq-server启用WEB管理
rabbitmq-plugins enable rabbitmq_management启动其他的
rabbitmq-plugins enable rabbitmq_tracing远程帐户配置
由于账号guest具有所有的操作权限,并且又是默认账号,出于安全因素的考虑,guest用户只能通过localhost登陆使用,并建议修改guest用户的密码以及新建其他账号管理使用rabbitmq。 这里我们以创建个sunday帐号,密码sunday为例,创建一个账号并支持远程ip访问。
rabbitmqctl add_user sunday sunday # 创建账号
rabbitmqctl set_user_tags sunday administrator # 设置用户角色
rabbitmqctl set_permissions -p "/" sunday ".*" ".*" ".*" # 设置用户权限
rabbitmqctl list_users # 查看用户列表
rabbitmqctl change_password username password # 修改用户密码WEB: 192.168.10.101:15672
为什么使用集群
- 允许消费者和生产者在Rabbit节点崩溃的情况下继续运行;
- 通过增加节点来扩展Rabbit处理更多的消息,承载更多的业务量;
集群的特点
RabbitMQ的集群是由多个节点组成的,但我们发现不是每个节点都有所有队列的完全拷贝。 RabbitMQ节点不完全拷贝特性 为什么默认情况下RabbitMQ不将所有队列内容和状态复制到所有节点?有两个原因:
- 存储空间 -- 如果每个节点都拥有所有队列的完全拷贝,这样新增节点不但没有新增存储空间,反而增加了更多的冗余数据。
- 性能 -- 如果消息的发布需安全拷贝到每一个集群节点,那么新增节点对网络和磁盘负载都会有增加,这样违背了建立集群的初衷,新增节点并没有提升处理消息的能力,最多是保持和单节点相同的性能甚至是更糟。
所以其他非所有者节点只知道队列的元数据,和指向该队列节点的指针。
集群节点类型
节点的存储类型分为两种:
- 磁盘节点
- 内存节点
磁盘节点就是配置信息和元信息存储在磁盘上,内存节点把这些信息存储在内存中,当然内存节点的性能是大大超越磁盘节点的。
单节点系统必须是磁盘节点,否则每次你重启RabbitMQ之后所有的系统配置信息都会丢失。
RabbitMQ要求集群中至少有一个磁盘节点,当节点加入和离开集群时,必须通知磁盘节点。
特殊异常:集群中唯一的磁盘节点崩溃了
如果集群中的唯一一个磁盘节点,结果这个磁盘节点还崩溃了,那会发生什么情况? 如果唯一磁盘的磁盘节点崩溃了,不能进行如下操作:
- 不能创建队列
- 不能创建交换器
- 不能创建绑定
- 不能添加用户
- 不能更改权限
- 不能添加和删除集群几点
总结:如果唯一磁盘的磁盘节点崩溃,集群是可以保持运行的,但你不能更改任何东西。 解决方案: 在集群中设置两个磁盘节点,只要一个可以,你就能正常操作。
群集架构图
生产环境使用还需要根据实际的业务需求对集群中的各个实例进行一些性能参数指标的监控,从性能、吞吐量和消息堆积能力等角度考虑,可以选择Kafka来作为RabbitMQ集群的监控队列使用。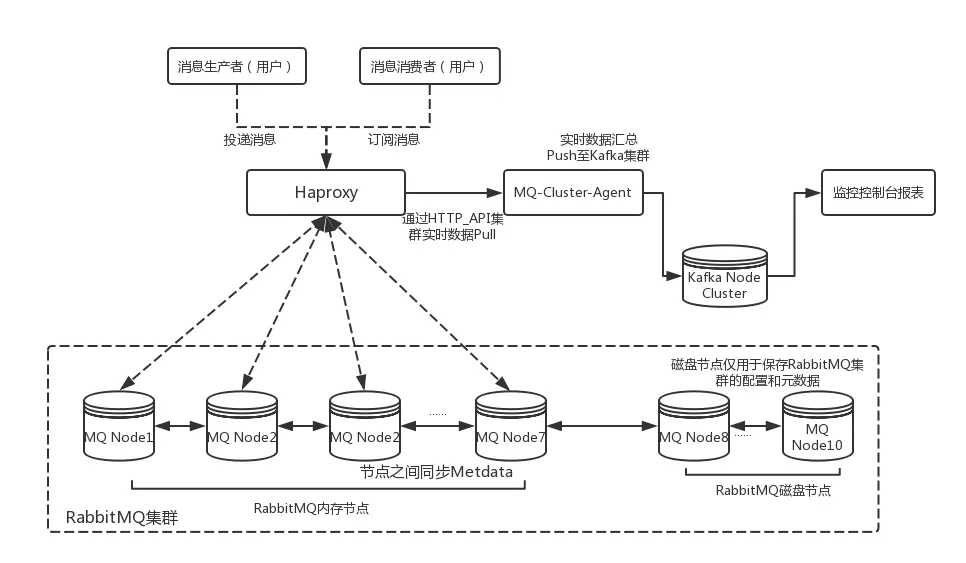
集群配置
拷贝同步.erlang.cookie
scp /var/lib/rabbitmq/.erlang.cookie root@node2:/var/lib/rabbitmq/
scp ... node3-10...
chown 400 /var/lib/rabbitmq/.erlang.cookie在node2-10执行以下命令(以node1为主节点,加入群集)
rabbitmqctl stop_app
# rabbitmqctl reset
rabbitmqctl join_cluster rabbit@node1
rabbitmqctl start_app配置部分内存节点
rabbitmqctl join_cluster rabbit@node1 --ram 或修改的节点的类型
rabbitmqctl stop_app
#rabbitmqctl change_cluster_node_type disc
rabbitmqctl change_cluster_node_type ram
rabbitmqctl start_app移除节点 软删除 如果想要把节点从集群中移除,可使用如下命令实现:
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
rabbitmqctl cluster_status硬删除 直接删掉集群中的某个节点
rabbitmqctl forget_cluster_node rabbit@Demo20集群重启顺序 集群重启的顺序是固定的,并且是相反的。 如下所述:
- 启动顺序:磁盘节点 => 内存节点
- 关闭顺序:内存节点 => 磁盘节点
最后关闭必须是磁盘节点,不然可能回造成集群启动失败、数据丢失等异常情况
查看集群
rabbitmqctl cluster_status
Cluster status of node rabbit@node1 ...
[{nodes,[{disc,[rabbit@node1,rabbit@node2,rabbit@node3]}]},
{running_nodes,[rabbit@node3,rabbit@node2,rabbit@node1]},
{cluster_name,<<"rabbit@node1">>},
{partitions,[]},
{alarms,[{rabbit@node3,[]},{rabbit@node2,[]},{rabbit@node1,[]}]}]镜像队列策略
在cluster中任意节点启用策略,队列会被复制到每个节点,各个节点状态保持一致。
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'添加其他虚拟主机
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}' --vhost xxx.com策略模式为 all 即复制到所有节点,包含新增节点, 策略正则表达式为 “^” 表示所有匹配所有队列名称。
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: queue的匹配模式(正则表达式)
Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params:ha-mode模式需要用到的参数
ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual(默认值)
priority:可选参数,policy的优先级ha-mode=all: 队列镜像到集群内所有的节点。当新节点加到集群中时,所有队列将都镜像到新增节点中。
ha-sync-mode 参数是用来控制新加入集群的镜像节点是否自动同步镜像队列中的消息;
默认情况下ha-sync-mode=manual ,表示新的队列镜像将不会接收已有消息,只会接收新消息,除非显式调用命令。需要注意的是,队列同步是一项阻塞操作。当调用同步命令后,队列开始阻塞,无法对其进行操作,直到同步完成;
手工同步队列
rabbitmqctl sync_queue name --vhost xxx.com取消手工同步队列
rabbitmqctl cancel_sync_queue name --vhost xxx.com查看集群中哪些节点已经完成了同步,哪些未完成同步
rabbitmqctl list_queues name slave_pids synchronised_slave_pids --vhost xxx.com当 ha-sync-mode=automatic 时,新加入节点时会默认同步已知的镜像队列。同步过程中所有的消息都会被阻塞,直到同步完成。
名称以"message"开头的队列相匹配,并将镜像配置到集群中的所有节点.
rabbitmqctl (Linux)
rabbitmqctl set_policy ha-all "^message." "{""ha-mode"":""all""}"
HTTP API
PUT /api/policies/%2f/ha-all {"pattern":"^message.", "definition":{"ha-mode":"all"}}
Web UI
Navigate to Admin > Policies > Add / update a policy.Enter "ha-all" next to Name, "^message."
next to Pattern, and "ha-mode" = "all" in the first line next to Policy.策略的名称以"two"开始的队列镜像到群集中的任意两个节点,并进行自动同步
rabbitmqctl rabbitmqctl set_policy ha-two "^two." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'以"node"开头的队列镜像到集群中的特定节点的策略:
rabbitmqctl set_policy ha-nodes "^nodes." '{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'配置HAProxy
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,开源快速并且可靠的一种解决方案。根据官方数据,其最高极限支持10G的并发。HAProxy支持从4层至7层的网络交换,即覆盖所有的TCP协议。支持 Mysql 的均衡负载。为了实现RabbitMQ集群的软负载均衡,这里可以选择HAProxy。
对于消息的生产和消费者可以通过HAProxy的软负载将请求分发至RabbitMQ集群中的Node1~Node7节点,其中Node8~Node10的三个节点作为磁盘节点保存集群元数据和配置信息。
HAProxy的具体配置 node1-7 内存节点组成集群的负载均衡,node8-10磁盘节点用于保存集群的配置和元数据,不做负载
global
maxconn 10000
stats socket /var/run/haproxy.stat mode 600 level admin
log 127.0.0.1 local0
uid 98
gid 98
chroot /var/empty
daemon
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
maxconn 10000
timeout connect 5s
timeout client 60s
timeout server 60s
listen rabbitmq_cluster
bind 0.0.0.0:5672
mode tcp
balance roundrobin
server rmq_node1 192.168.10.101:5672 check inter 2000 rise 2 fall 3 weight 1
server rmq_node2 192.168.10.102:5672 check inter 2000 rise 2 fall 3 weight 1
server rmq_node3 192.168.10.103:5672 check inter 2000 rise 2 fall 3 weight 1
server rmq_node4 192.168.10.104:5672 check inter 2000 rise 2 fall 3 weight 1
server rmq_node5 192.168.10.105:5672 check inter 2000 rise 2 fall 3 weight 1
server rmq_node6 192.168.10.106:5672 check inter 2000 rise 2 fall 3 weight 1
server rmq_node7 192.168.10.107:5672 check inter 2000 rise 2 fall 3 weight 1
listen rabbitmq_web
bind 0.0.0.0:15672
mode http
balance source
server rmq_node1 192.168.10.101:15672 check inter 2000 rise 2 fall 1 weight 1
server rmq_node2 192.168.10.102:15672 check inter 2000 rise 2 fall 1 weight 1
server rmq_node3 192.168.10.103:15672 check inter 2000 rise 2 fall 1 weight 1
#...
listen monitor
bind 0.0.0.0:8100
mode http
stats enable
stats uri /stats
stats refresh 5s参数解释: server rmq_node1 192.168.10.101:5672 check inter 2000 rise 2 fall 3 weight 1
- server :定义HAProxy内RabbitMQ服务的标识;
- ip1:5672:后端RabbitMQ的服务器IP地址;
- check inter :表示每隔多少毫秒检查RabbitMQ服务是否可用;
- rise :表示RabbitMQ服务在发生故障之后,需要多少次健康检查才能被再次确认可用;
- fall :表示需要经历多少次失败的健康检查之后,HAProxy才会停止使用此RabbitMQ服务。
HAPrxoy Web: http://192.168.10.100:8100/stats
配置Keepalived
主Keppalived
global_defs {
# 路由id,主备节点不能相同
router_id node1
}
# 自定义监控脚本
vrrp_script chk_haproxy {
# 脚本位置
script "/etc/keepalived/haproxy_check.sh"
# 脚本执行的时间间隔
interval 5
weight 10
}
vrrp_instance VI_1 {
# Keepalived的角色,MASTER 表示主节点,BACKUP 表示备份节点
state MASTER
# 指定监测的网卡,可以使用 ifconfig 进行查看
interface enp0s8
# 虚拟路由的id,主备节点需要设置为相同
virtual_router_id 1
# 优先级,主节点的优先级需要设置比备份节点高
priority 100
# 设置主备之间的检查时间,单位为秒
advert_int 1
# 定义验证类型和密码
authentication {
auth_type PASS
auth_pass 123456
}
# 调用上面自定义的监控脚本
track_script {
chk_haproxy
}
virtual_ipaddress {
# 虚拟IP地址,可以设置多个
192.168.10.100
}
}备Keepalived
global_defs {
# 路由id,主备节点不能相同
router_id node2
}
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh"
interval 5
weight 10
}
vrrp_instance VI_1 {
# BACKUP 表示备份节点
state BACKUP
interface enp0s8
virtual_router_id 1
# 优先级,备份节点要比主节点低
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
track_script {
chk_haproxy
}
virtual_ipaddress {
192.168.10.100
}
}使用 haproxy_check.sh脚本对 HAProxy 进行监控:
#!/bin/bash
# 判断haproxy是否已经启动
if [ ${ps -C haproxy --no-header |wc -l} -eq 0 ] ; then
#如果没有启动,则启动
haproxy -f /etc/haproxy/haproxy.cfg
fi
#睡眠3秒以便haproxy完全启动
sleep 3
#如果haproxy还是没有启动,此时需要将本机的keepalived服务停掉,以便让VIP自动漂移到另外一台haproxy
if [ ${ps -C haproxy --no-header |wc -l} -eq 0 ] ; then
systemctl stop keepalived
fi启动服务
systemctl start keepalived在主Keepalived使用ip a 命令查看到虚拟 IP 的情况:
验证故障转移
这里我们验证一下故障转移检,如果 HAProxy 已经停止且无法重启时 KeepAlived 服务就会停止,这里我们直接使用以下命令停止测试
#测试1
systemctl stop haproxy
#测试2
systemctl stop keepalived两个测试,分别使用 ip a 分别查看,VIP 都会漂移到 备Keepalived服务器
压力测试
wget https://github.com/rabbitmq/rabbitmq-perf-test/releases/download/v2.3.0/rabbitmq-perf-test-2.3.0-bin.tar.gz
./runjava com.rabbitmq.perf.PerfTest -x100 -y100 -e"testex" -t"fanout" -u"testque" -k"kk01"
openjdk错误解决
which: no javac in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin)
JAVA_HOME not set and cannot find javac to deduce location, please set JAVA_HOME.
yum install -y java-1.8.0-openjdk-devel参考
消息中间件—RabbitMQ(集群原理与搭建篇) RabbitMQ官方群集文档
RabbitMQ系列(六)你不知道的RabbitMQ集群架构全解
RabbitMQ 高可用之镜像队列
RabbitMQ高可用镜像队列

